Decoding the Role of Federated Learning in Preserving Privacy Across Connected Devices
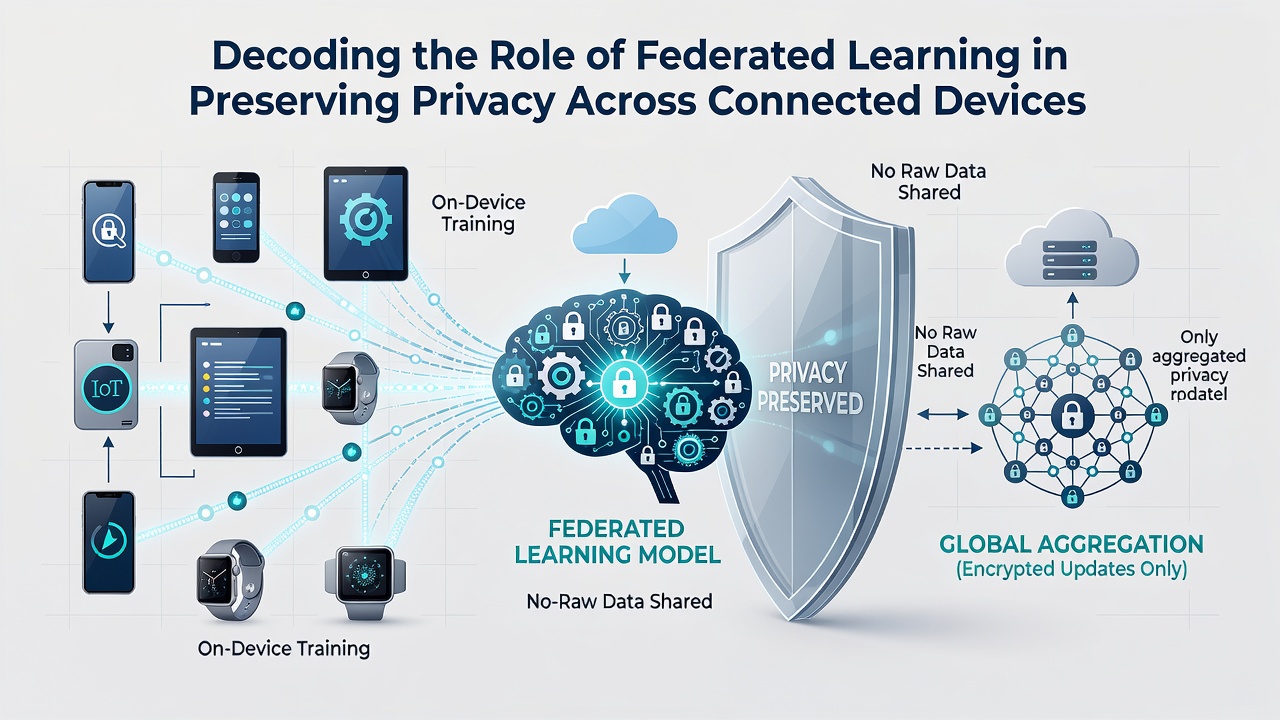
Connected devices generate vast amounts of data every day, yet traditional machine learning approaches often require centralizing that information which creates clear privacy risks, and federated learning changes the equation by keeping raw data on individual devices while still enabling model improvements across networks. Researchers have observed that this distributed training method allows devices such as smartphones, wearables, and industrial sensors to contribute to collective intelligence without exposing personal details to external servers.
How Federated Learning Operates in Practice
Devices train local models on their own datasets then transmit only the updated parameters back to a central coordinator, and secure aggregation techniques combine those updates so no single contribution can be traced to its source. This process repeats over multiple rounds while differential privacy mechanisms add calibrated noise to further obscure individual inputs. Observers note that the approach scales effectively because computation happens at the edge where data already resides.
Studies from academic institutions show that convergence rates remain comparable to centralized training when communication protocols are optimized, although bandwidth constraints in some IoT environments can slow progress. Those who've implemented the system report that client selection strategies help maintain efficiency by prioritizing devices with sufficient compute resources and stable connections.
Privacy Mechanisms and Regulatory Alignment
Federated learning aligns with data minimization principles outlined in frameworks such as the EU's GDPR and Canada's PIPEDA because personal information never leaves the device, and this characteristic reduces exposure during transmission. According to guidance from the National Institute of Standards and Technology, combining federated methods with encryption at rest strengthens protections against both external breaches and insider threats.
One research team documented how gradient compression and quantization further limit the amount of information that could theoretically be reconstructed from model updates, and these techniques have become standard in production deployments. The reality is that no single safeguard provides complete anonymity, which is why layered defenses receive emphasis in current implementations.
Applications Across Device Ecosystems
Smartphone keyboards use federated learning to improve next-word prediction while keeping typing histories private, and similar patterns appear in health monitoring wearables that refine anomaly detection models without uploading raw biometric readings. Industrial settings apply the same approach to predictive maintenance on factory equipment where proprietary sensor data must remain on-premises.
By June 2026 several automotive manufacturers had integrated federated pipelines into connected vehicle platforms to enhance driver assistance algorithms using data from millions of cars without centralizing location histories. Those deployments demonstrate how the technology supports both personalization and collective learning across geographically dispersed fleets.
Technical Challenges and Mitigation Strategies
Device heterogeneity creates uneven participation because older hardware trains more slowly or drops out mid-round, and system designers counter this by introducing adaptive aggregation weights that downplay contributions from less reliable clients. Non-IID data distributions across users can also bias global models toward dominant patterns, prompting research into personalization layers that fine-tune locally after global updates arrive.
Security researchers have identified potential poisoning attacks where malicious devices submit corrupted updates, and defense mechanisms such as robust aggregation rules or anomaly detection on parameter space have shown effectiveness in controlled tests. Communication overhead remains another constraint, particularly on cellular networks, leading to the adoption of update sparsification methods that transmit only significant changes.
Future Directions in Standards and Deployment
Industry consortia continue developing open protocols that facilitate interoperability between different device vendors and cloud platforms, and early specifications emphasize auditability of privacy guarantees. Academic papers published in 2025 explored integration with trusted execution environments to add hardware-level isolation for local training processes.
Regulatory bodies in multiple regions have begun referencing federated approaches in guidance documents on privacy-enhancing technologies, signaling broader acceptance as evidence of real-world efficacy accumulates. Those monitoring the space note that ongoing work on verifiable differential privacy aims to provide mathematical assurances that regulators and users can both understand.
Conclusion
Federated learning enables collaborative model development across connected devices while maintaining data locality, and its combination with existing privacy tools addresses many concerns associated with centralized collection. Continued refinement of communication efficiency, attack resistance, and fairness across heterogeneous participants will determine how widely the technique expands into new device categories. Current deployments already illustrate practical value in consumer electronics and industrial systems, and further standardization efforts should support even broader adoption.